- Published on
My Research Paper Reading Routine in 3 steps
- Authors
- Name
- Yann Le Guilly
- @yannlg_


0. Preparation
Before talking about the routine itself, here are the tools and resources I'm using daily.
0.1. Notion for keeping track of my readings
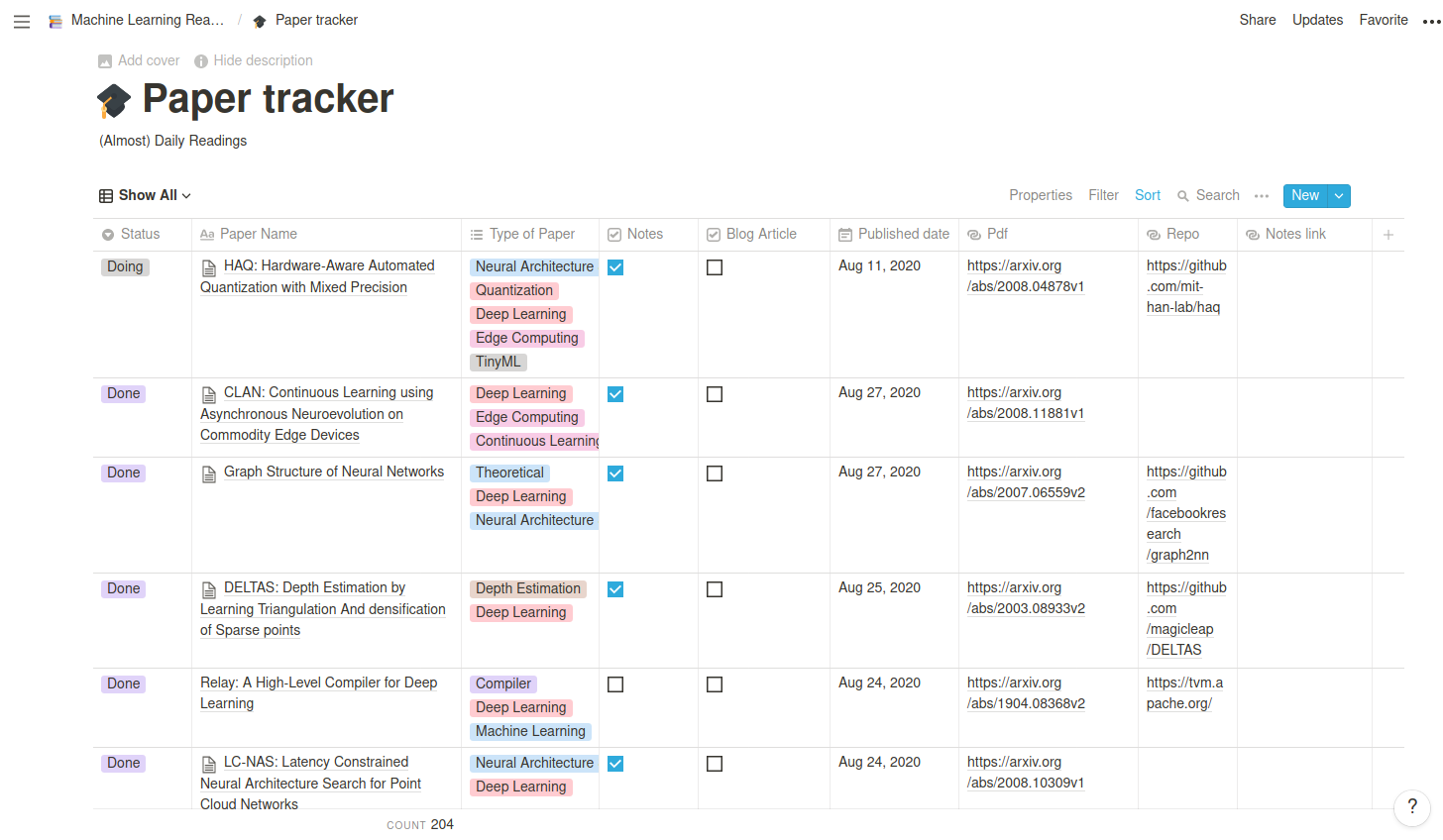
A friend introduced me to this tool last year and I could successfully integrate it into different routines that I have. If you don't know it already, it's similar to Evernote. You can create an account there.
I'm using notion to keep track and label the papers I'm reading. Sometimes I also write notes.
0.2. Resources I'm using mainly 3 websites: - www.arxiv-sanity.com/ - https://paperswithcode.com/
1. The routine
1.1. Step 1: Looking at the newest papers
Everyday the first thing I'm doing is visiting arxiv-sanity most recent.


At this point, I'm reading mainly the titles and rapidly the abstracts. Usually, I open 2-3 papers that might interest me in a new tab.
1.2. Step 2: Getting the general idea
For each paper, I'm opening the pdf.
- The abstract
The abstract is very useful and will give you an idea of the content. I usually read it a few times before starting to read the paper itself. - End of the introduction
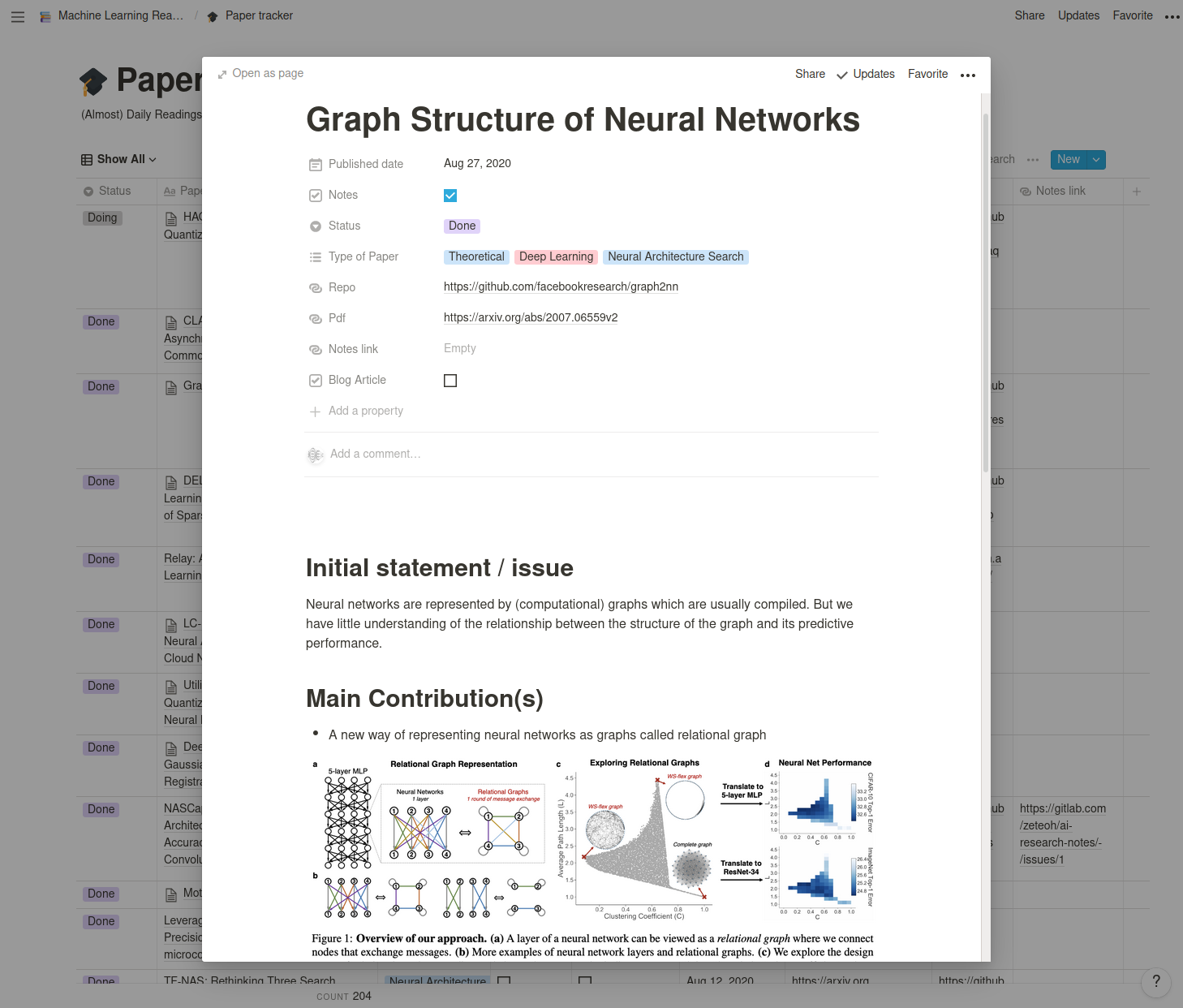
Then I'm reading the end of the introduction. Usually, the authors sum up the most important points of their contribution by writing "Our contribution..." or "In this work...".The next part is oftenrelated work. If I only want to get a general idea on the paper I'm skipping this. - Diagram which represents the method
It is common that the authors are providing a diagram of their method. Sometimes I'm totally lost looking at it though...
- Experimentations
Finally, I'm looking at the experimentations. This can be super tricky to read though, so I don't really rely on a simple overview of the results. I'm more interested in the datasets and to what the actual work is compared with (baselines).


1.3. Step 3: paperswithcode
Then I'm usually visiting https://paperswithcode.com/. I feel less intuitive to use that axiv-sanity but it has other advantages. I totally ignore the feed Trending and go directly to Latest. Since it's mostly redundant with what I just did, I'm doing this very fast. I mostly look at the git repositories briefly if I see a lot of stars.
2. Recommendations and Advice
2.1. How to choose the topic(s)
In the beginning, I was quite lost about the topic I should focus on. So I read all the titles that looked interesting. Step by step I could focus on specific topics: compression (pruning, quantization, etc), neural architecture search, self-supervised learning, IoT/tinyML.
2.2. Going deeper
Sometimes I want to go deeper in a specific field. For that, I'm using the related work section and https://scholar.google.com/ to find related recent works with the button Cited by .... Arxiv has a similar feature.
2.3. Understanding I personally often don't get exactly how a method is working. But that's ok. If
I really need to understand the paper, I'm just spending more time on it. Sometimes 2 or 3 hours.
2.4. Conferences
Some very talented people are writing summaries of the main conferences. This can be super useful!
2.5. State-of-the-art
When I want to know the SOTA in a specific topic (often to compare with the experimentation section of a paper) I'm using paperswithcode.


2.6. Hype Even by doing this every day, I often miss great papers. So 3-4 times per month I check
the section top hype and top recent of arxiv-sanity. Twitter is also a great way to get the latest trends.
3. Conclusion
I could make this routine a real habit and read about 200 papers since January. My paper tracker is publicly available here. Hope this can be useful for you!